


5 takeaways from Designing a rate limiter from System Design Interview: an Insider's Guide



I started reading System Design Interview: an Insider's Guide after reading a post by Gergely Orosz recommending it. I have always wanted to learn more about system design and have not had the opportunity at work to do so.
These are my learnings from Chapter 4: Design a Rate Limiter.
Really understand the problem before designing
My first takeaway was how much information you actually need to have before diving into the design. While the context in this chapter features the interaction between an interviewer and software engineering candidate, this can apply to when you want to design your own rate limiter.
Some questions you might ask are:
- What is the rate limiter for?
- Is this a client or server side rate limiter?
- How do we throttle API requests? Via IP address, user IDs, or something else?
- What is the scale of the system we are building for?
- Would the limiter be built into the application, or is it a service by itself?
- Do users need to know if they are being rate limited?
With these questions, you would be able to narrow down the requirements for your rate limiter.
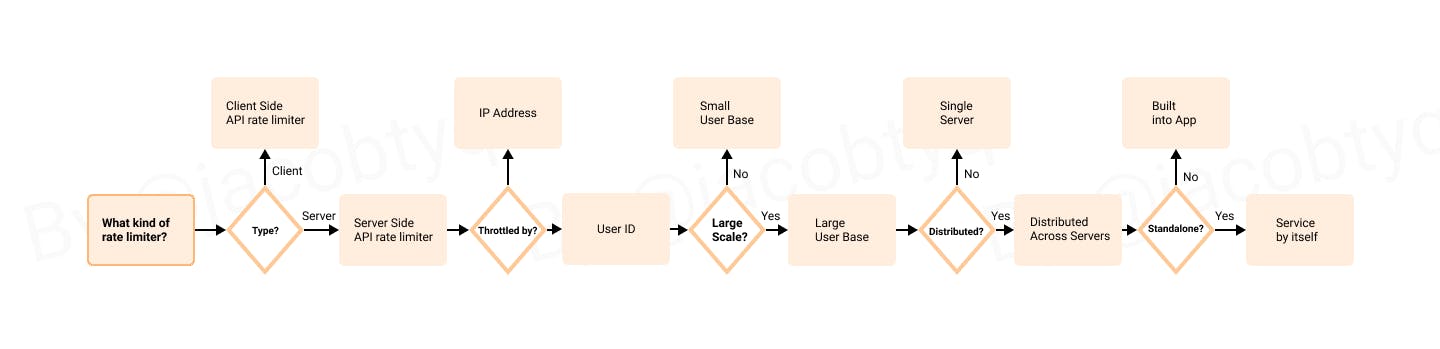
A simplistic flow-chart based off the questions you might ask
We can gather that the rate limiter would need to fulfil the following:
- Server side API rate limiter
- Throttles by User ID
- Cover a large user base
- Distributed across servers
- Is a service by itself
There is no absolute answer to where the rate limiter should be placed
Prior to reading this book, I would have thought that a rate limiter would always be placed on the server. I have since realised that my assumption was wrong and it ultimately depends on your current stack, resources, and priorities.
Some guidelines include:
- Is the language you are using efficient in implementing rate limiting?
- Do you need full control of the algorithm?
- Do you have resources to build a rate limiter at this time?
- Can your servers support the rate limiter you want to build?
- Could you use a 3rd party service for rate limiting?
There are so many algorithms that can be used in the design of a rate limiter
I had always assumed that rate limiters only allowed requests to be made at a fixed rate over a time period and learnt that there is actually a name for this algorithm - Token Bucket. Aside from that, there are various other algorithms that can be used.
The popular ones include:
- Token Bucket
- Leaking Bucket
- Fixed window counter
- Sliding window log
- Sliding window counter
I will not be covering how each algorithm works in this post.
Remember to add rate limiter headers
Without rate limiter headers, the client would not be able to know the following:
- Whether it is being throttled
- What is the limit of requests the client can make
- How many remaining requests can the client make?
- When does the rate limit reset?
Such information usually lies in the HTTP response headers, and the rate limiter will return the following headers to clients:
429 Too Many Requests -> How does the client know whether it is being throttled?
X-Ratelimit-Limit -> What is the limit of requests the client can make.
X-Ratelimit-Remaining -> How many remaining requests can the client make?
X-Rate-Limit-Reset -> Time till when does the rate limit reset?
Rate limiter HTTP Headers
Challenges in a distributed environment
While building a rate limiter for a single server environment may not be difficult, scaling the limiter to support multiple servers comes with a different set of challenges.
These challenges include:
- Race condition
- Synchronisation issues
Race condition
Race conditions happen a lot in concurrent environments. This occurs when you use a "get-increment-set" approach whereby your rate limiter retrieves the current rate limit counter, increments it, and pushes it back to the data store. The problem with this model is that there may be additional requests that come in before a full "get-increment-set", causing each request to believe they have the correct increment value.
Some strategies to tackle this include using locks to prevent other processes from accessing or writing to the counter, or a "set-then-get" approach.
Synchronisation Issues
Synchronisation is another factor to consider as well. If you have multiple rate limiters, synchronisation will be required.
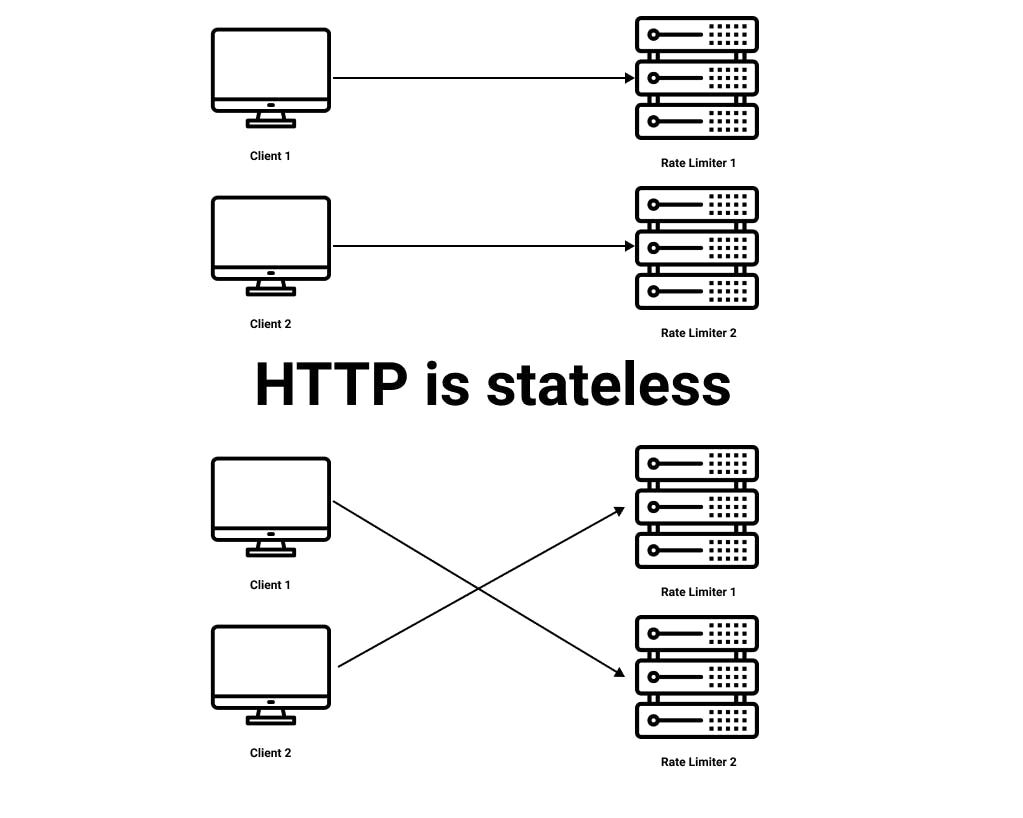
HTTP is stateless
For example, client 1 sends a request to rate limiter 1, and client 2 sends a request to rate limiter 2. As the HTTP protocol is stateless, clients can send requests to a different rate limiter. If client 1 sends a request to rate limiter 2 and rate limiter 2 does not have any data on client 1, it cannot work properly.
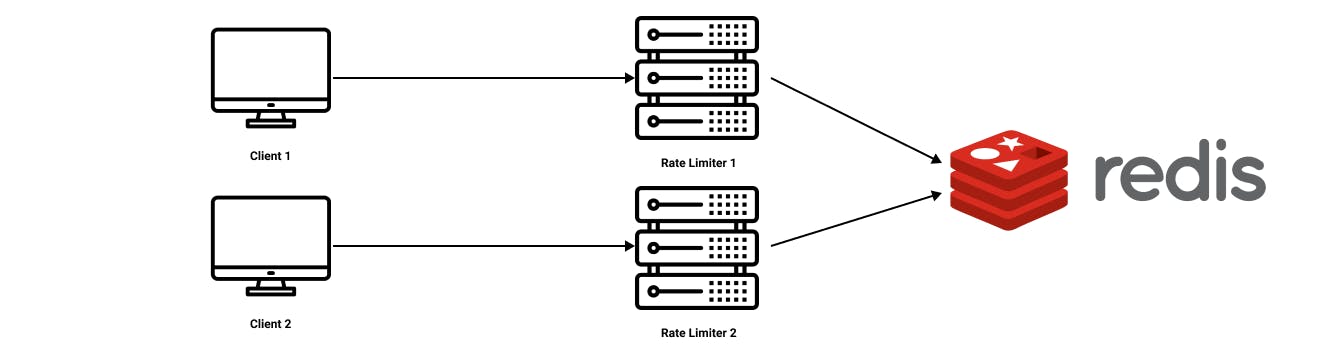
One approach to tackle this issue is by using a centralised data store like REDIS to handle rate limiting.
Other rate limiter design resources
There are other resources I found while writing this post
- An alternative approach to rate limiting by Nikrad Mahdi, a Software Engineer at Figma
- System Design — Rate limiter and Data modelling by Sai Sandeep Mopuri
- Rate-limiting strategies and techniques from Google's Cloud Architecture Center
- How to Design a Scalable Rate Limiting Algorithm by Guanlan Dai
- Rate limiting your RESTful API by Guillaume Viguier-Just